

Hi there! I’m Simone Santoni, an economic sociologist with a taste for fancy methods 
It seems you landed on my ’NLP, Organizations, and Markets’ GitHub Page. Here, you can find ideas, toolkits, and examples showing how to harness NLP to understand the functioning of organizations and markets. You’ll also come across ‘theoretical stuff’ regarding the foundations of NLP and some prominent algorithms (e.g., Mikolov et al’s word2vec).
Mainly, this GitHub Page condensates five years of experience I developed by researching, using, and teaching NLP. Talking about teaching: during the Summer Term of 2022, I’ll be offering a course on NLP for the MSc students of Bayes Business School (formerly, Cass Business School). I’ll expand the materials available in this GitHub Page on a rolling basis as I go through the various weeks of my NLP course, ending on the first week of July. Meanwhile… hang tight
Scope
What you’ll find in this GitHub page
Key aspects of algorithms playing a core role in NLP (e.g., word2vec)
A high-level description of prominent NLP tools (e.g., topic modeling)
Examples showing how to use prominent NLP tools to get a closer understanding of organizations and markets
Python scripts to deploy ‘as is’ or adapt to make things happen
Sample datasets
… and what you won’t find
A comprehensive survey of NLP-related algorithms and tools
Materials on NLP applications that pursue operational goals (e.g., chatbots, translation)
Advice on how to improve the performance of extant NLP-related algorithms
Building blocks
How to approach the individual building blocks
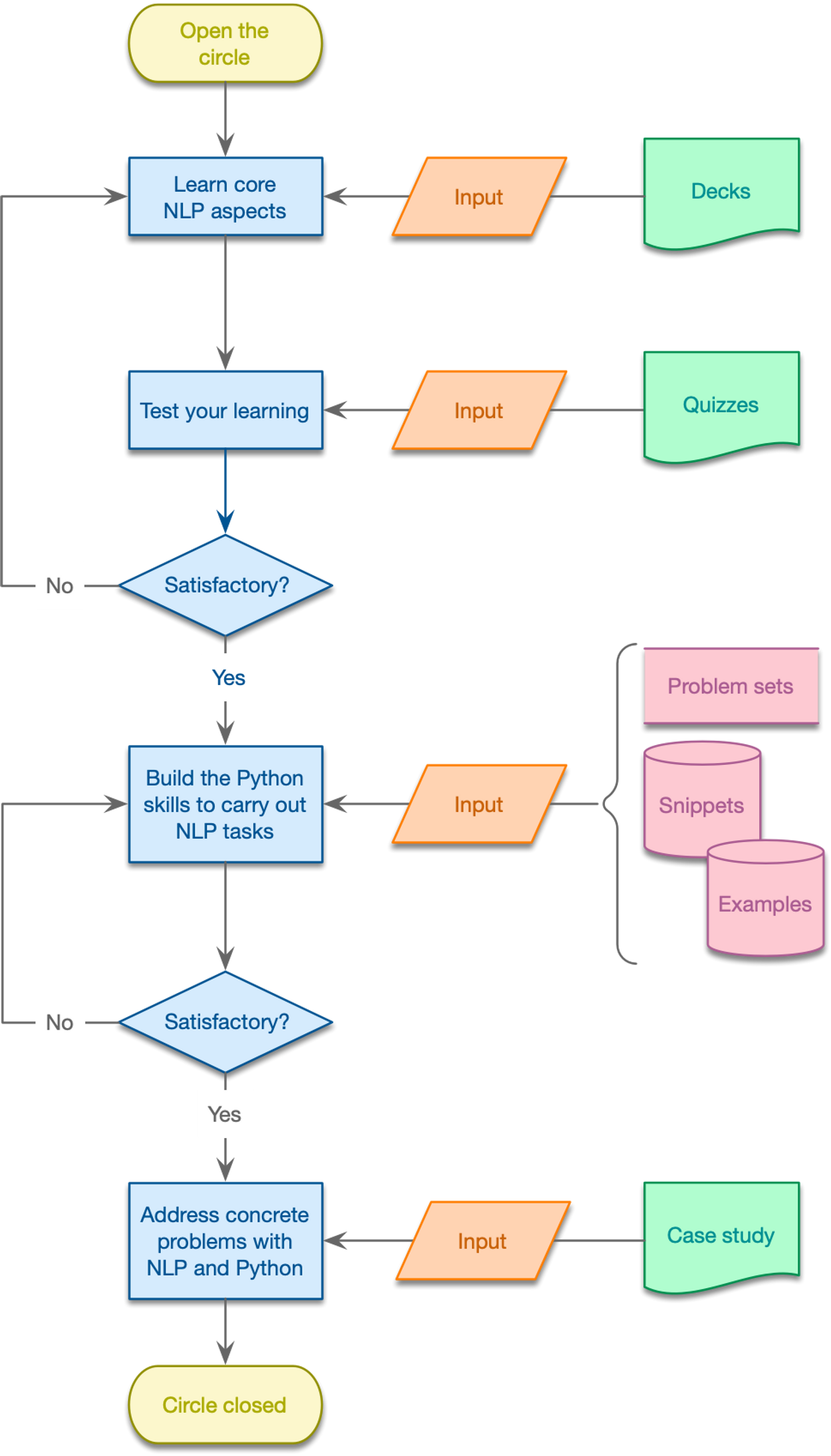
Goals
If you’re stubborn enough to engage with all my materials , then you may (say, will ) be able to:
) be able to:clean, prepare, and transform text corpora containing organization- and marker-level data
design and operate a variety of NLP pipelines
associate the most appropriate NLP framework/tools with specific analytic problems
translate NLP outcomes into valuable insights regarding organizations and markets
Materials
Materials are organized around NLP tools. For each NLP tool, I provide a learning package comprising a chunk of (narrated) decks, quizzes to self-evaluate your learning, Python scripts and problem sets to consolidate your NLP skills, and case studies showing how to mobilize NLP tools to address relevant problems concerning the functioning of organizations and markets.
NLP tools. For each NLP tool, I provide a learning package comprising a chunk of (narrated) decks, quizzes to self-evaluate your learning, Python scripts and problem sets to consolidate your NLP skills, and case studies showing how to mobilize NLP tools to address relevant problems concerning the functioning of organizations and markets.





For Bayes Business School students

The Moodle page of SMM694 contains all the important information regarding the organization of the module I’ll be teaching over Summer 2022. Students are required to refer to the Moodle page . In the interest of redundancy, here, I report some critical information such as the calendar of lectures, a suggested timelines — i.e., what to study when — and the text of the assignments.
. In the interest of redundancy, here, I report some critical information such as the calendar of lectures, a suggested timelines — i.e., what to study when — and the text of the assignments.Spotlight
The economic relevance of NLP




Where NLP comes from




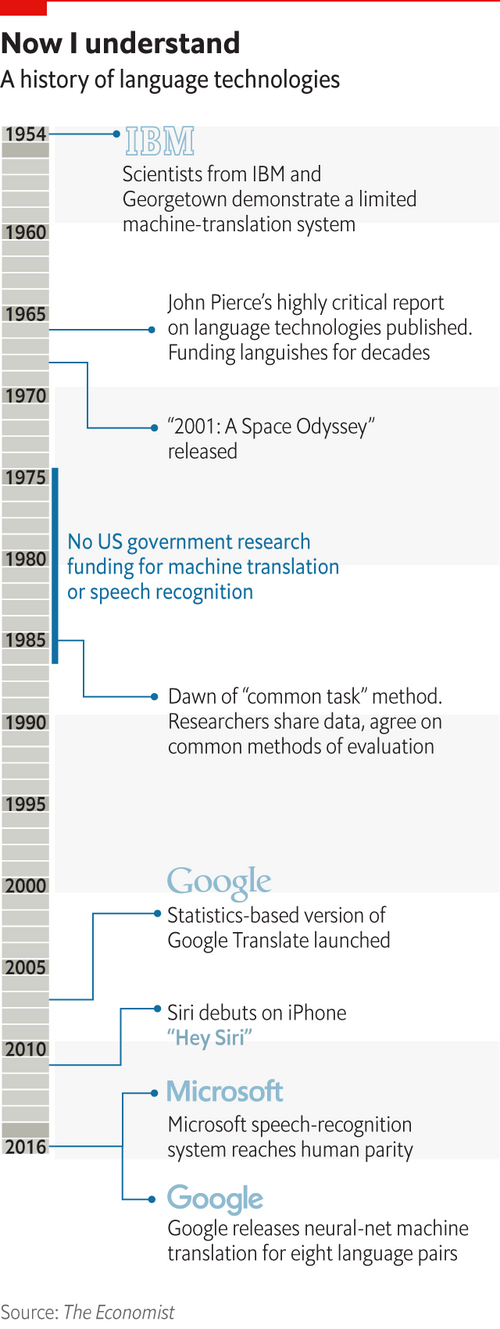


r/

FAQ
Who is this for?
People with a minimal programming background and a taste for analyzing organizations and markets
Why did you build this?
Because I think NLP tools can radically advance our understanding of organization and markets — however, NLP tools are still limitedly diffused
How to use this?
Familiarize with NLP tools — test your knowledge — apply what you learn to problems regarding organizations and markets
Love this GitHub Page?
Share your contacts by dropping a line to simone.santoni.1@city.ac.uk
09:10