Network Centrality
Measuring Importance and Influence in Networks
Closeness Centrality
Definition: Inverse of average distance to all other nodes
\[C_C(i) = \frac{n-1}{\sum_{j \neq i} d(i,j)}\]
where \(d(i,j)\) is the shortest path distance from \(i\) to \(j\)
Alternative (Harmonic Mean):
\[C_C^{harm}(i) = \sum_{j \neq i} \frac{1}{d(i,j)}\]
Intuition: How quickly can node \(i\) reach everyone else?
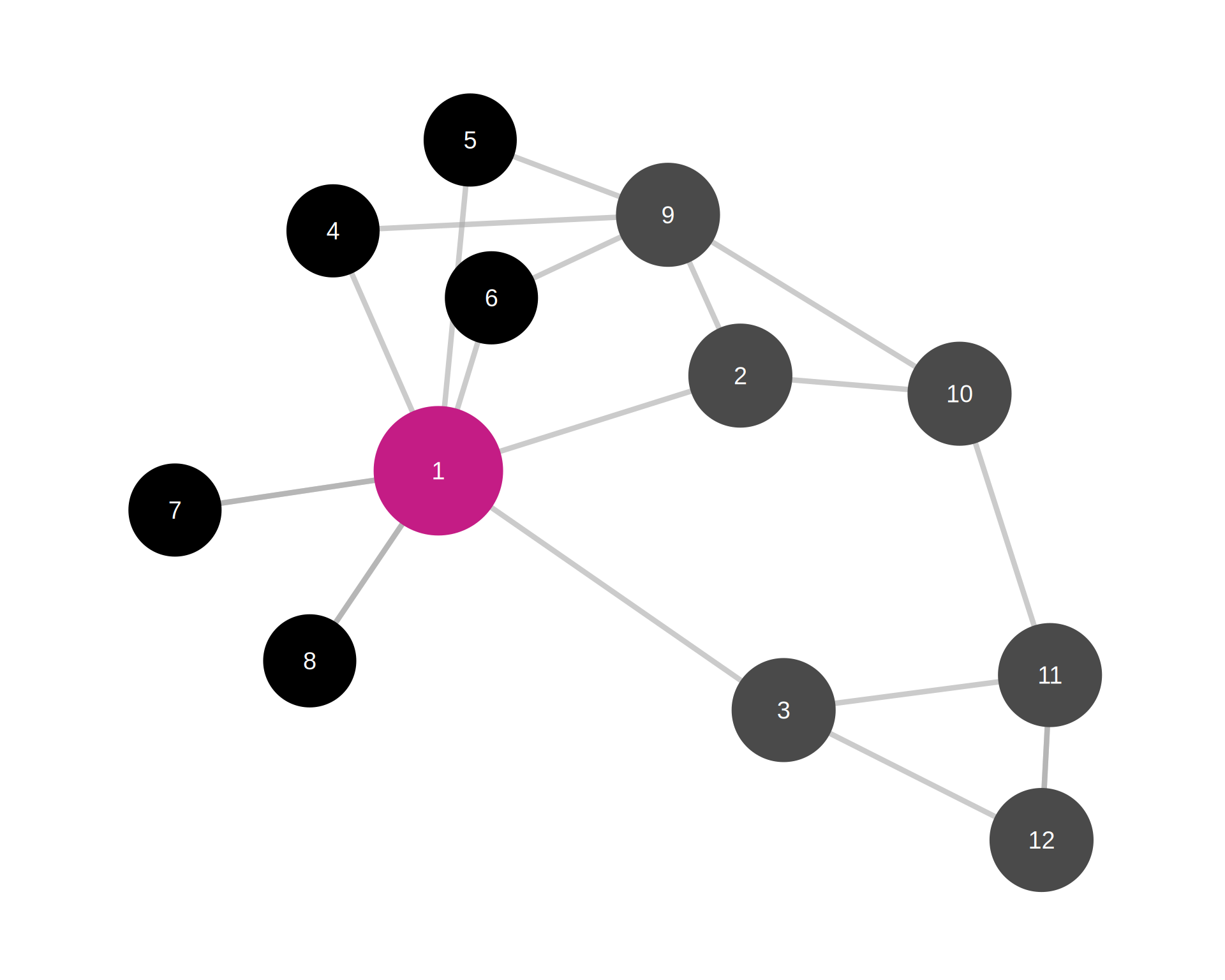
Note
Magenta path: Shortest path between nodes 3 and 10 is through 4 and 9
Closeness considers the shortest path between node \(i\) and all other nodes in the network
Closeness Example: Knowledge Networks
Engineering Consulting Firm
High Closeness Engineer (avg distance = 2.1)
- Can quickly reach any expertise in the firm
- Efficient problem-solving through quick consultation
- Ideal for project coordination roles
- Fast knowledge integration
Low Closeness Engineer (avg distance = 4.8)
- Isolated in organizational periphery
- Slower access to firm-wide expertise
- May develop specialized deep knowledge
- Potential: Mentorship to improve integration
Strategic Implication: Closeness predicts coordination effectiveness
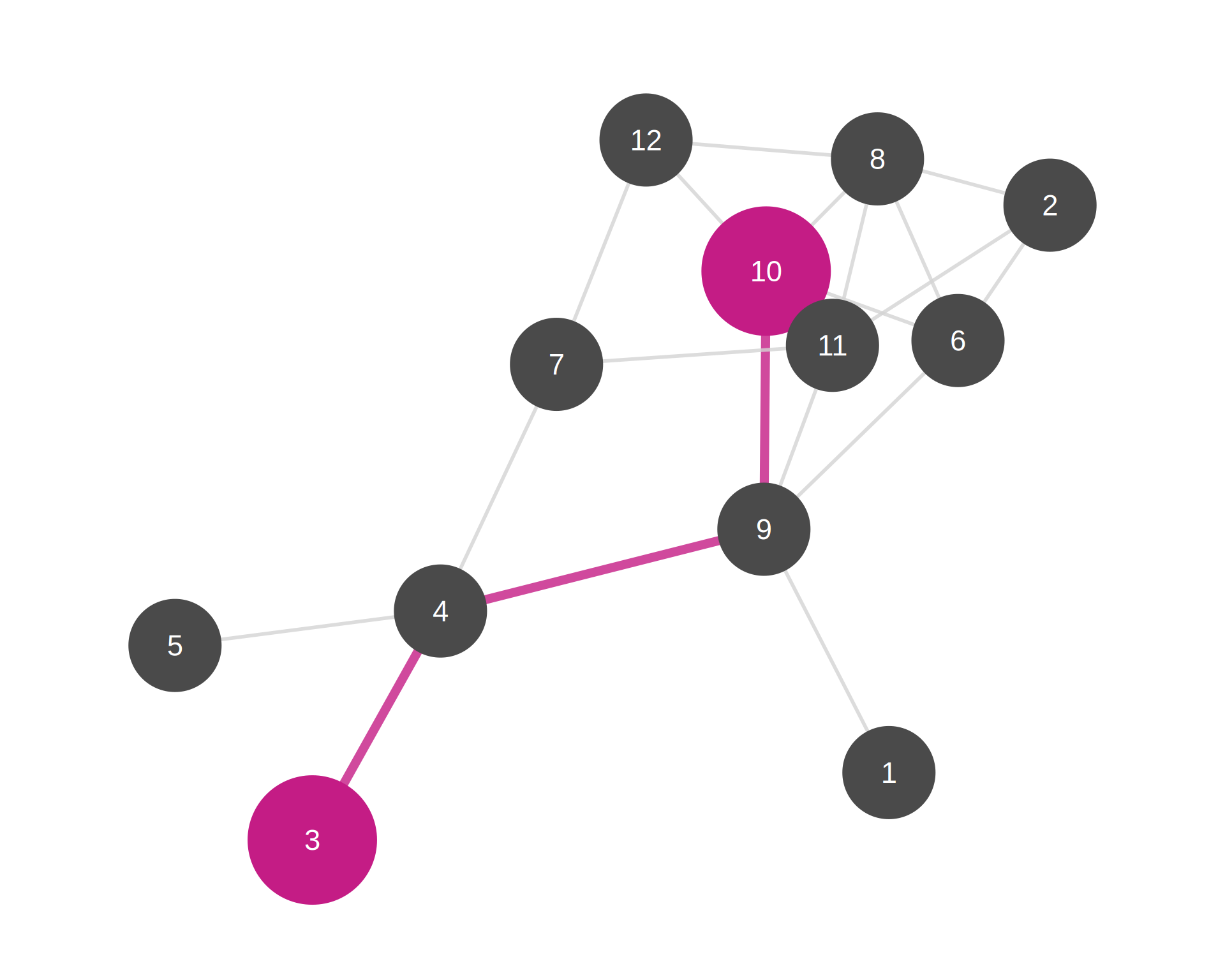
Note
Magenta node: High closeness (central position)
Black node: Low closeness (peripheral position)
Betweenness Example: Innovation Networks
Pharmaceutical R&D Network
High Betweenness Scientist (bridges Chemistry & Biology labs)
- Unique position connecting two specialized domains
- Controls knowledge transfer between groups
- First to see combination opportunities
- Career advantage: Valuable to both groups
- Organizational value: Enables cross-disciplinary projects
Low Betweenness Scientist (within dense cluster)
- Embedded in single community
- Many redundant paths don’t pass through them
- Deep specialization possible
- Innovation: Incremental improvements
Finding: High betweenness predicts cross-disciplinary breakthroughs
Note
Magenta node: High betweenness (broker position)
Black node: Low betweenness (embedded in group)
Eigenvector Centrality: Quality vs. Quantity
Degree vs. Eigenvector:
- Degree: Counts all connections equally (1 point per neighbor)
- Eigenvector: Weights neighbors by their importance
Example Scenarios:
Scenario A: High Degree, Low Eigenvector
- 50 connections to peripheral nodes
- “Popular among the unpopular”
- Volume without prestige
Scenario B: Low Degree, High Eigenvector
- 3 connections to highly central nodes
- “Connected to the elite”
- Quality over quantity
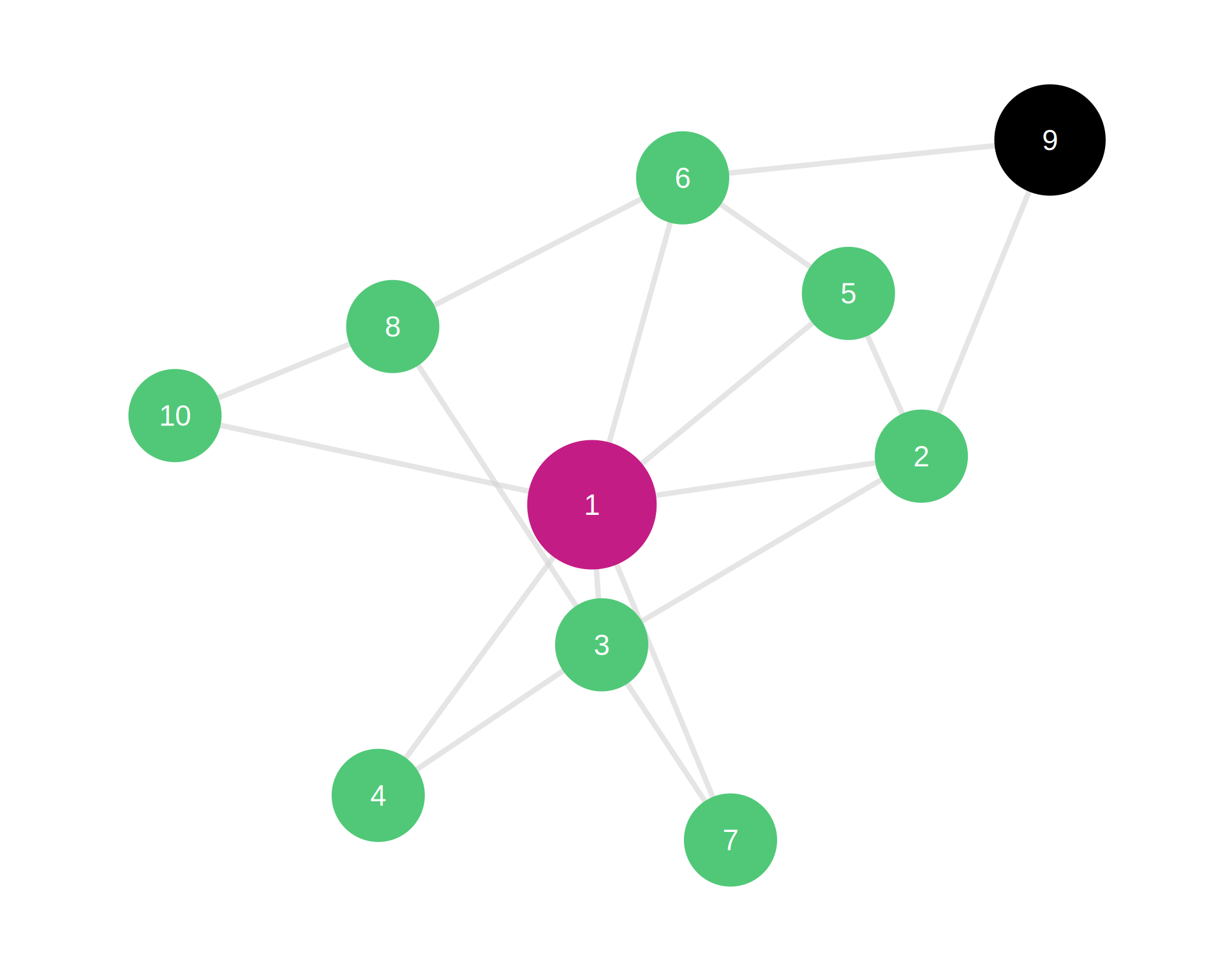
Note
Classic Example: Craig Robinson (former Oregon State basketball coach) has high eigenvector centrality because he’s President Obama’s brother-in-law
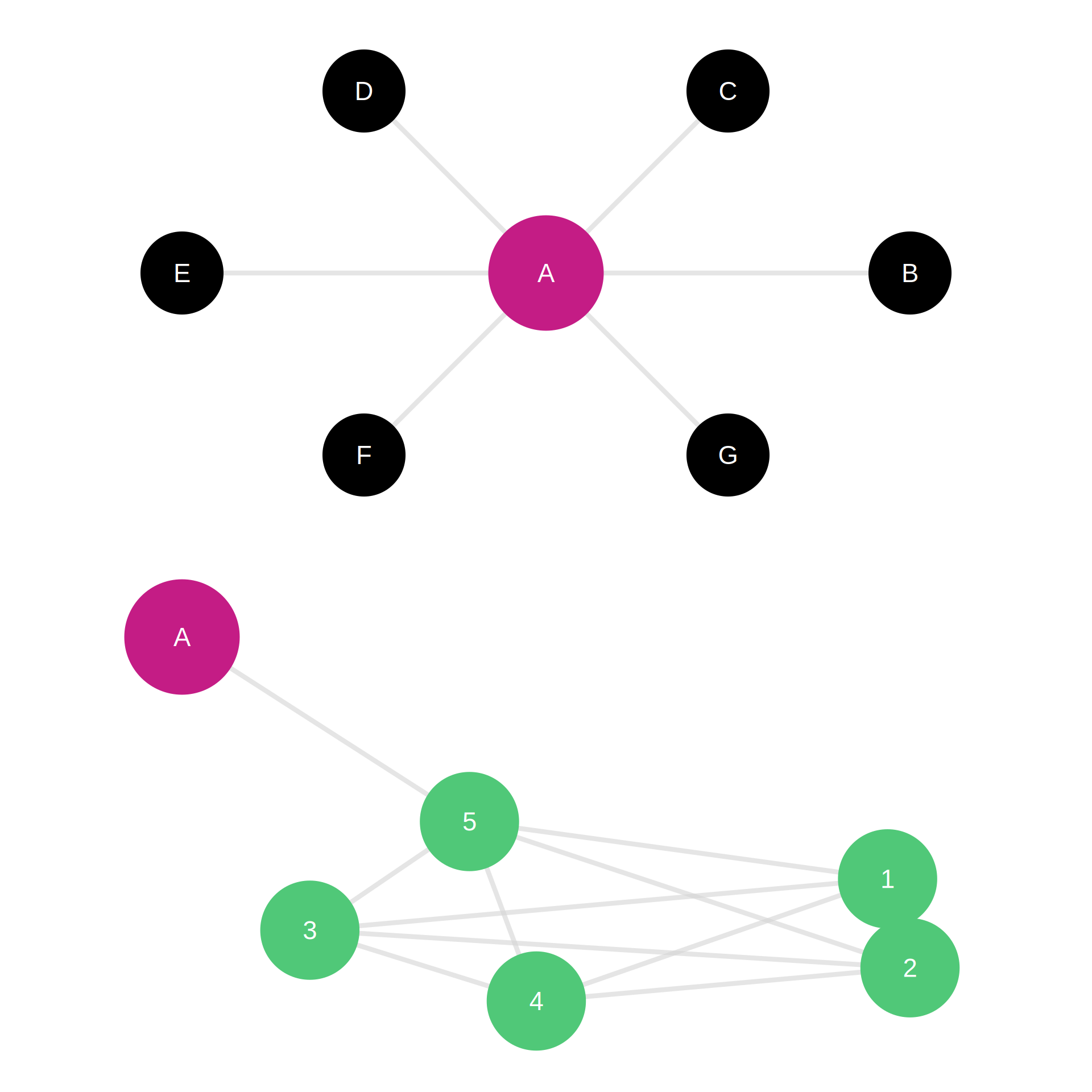
Note
Top network (Scenario A): Node A (magenta) has high degree (6 connections) but low eigenvector centrality (connected to peripheral nodes shown in black)
Bottom network (Scenario B): Node A (magenta) has low degree (1 connection) but high eigenvector centrality (connected to highly central cluster shown in emerald)
Clustering Coefficient
Definition: Proportion of neighbors that are also connected
\[C_{clust}(i) = \frac{2e_i}{k_i(k_i-1)}\]
where:
- \(k_i\) = degree of node \(i\)
- \(e_i\) = number of edges between neighbors of \(i\)
Interpretation: How interconnected is node \(i\)’s neighborhood?
Range: 0 (no neighbors connected) to 1 (all neighbors connected)
Key Insight:
- Closed triad: Node’s neighbors are connected → High clustering
- Open triad: Node’s neighbors are not connected → Low clustering
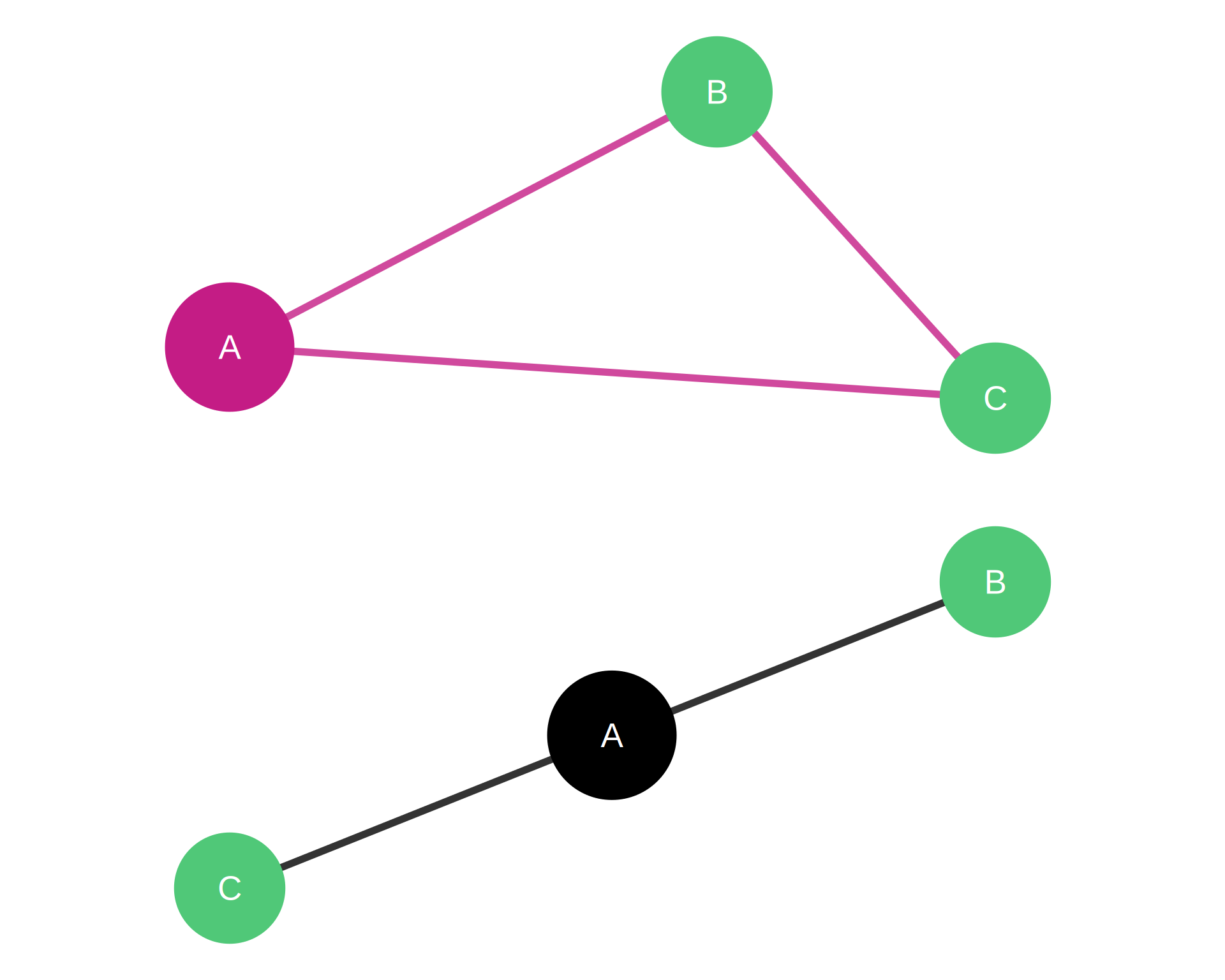
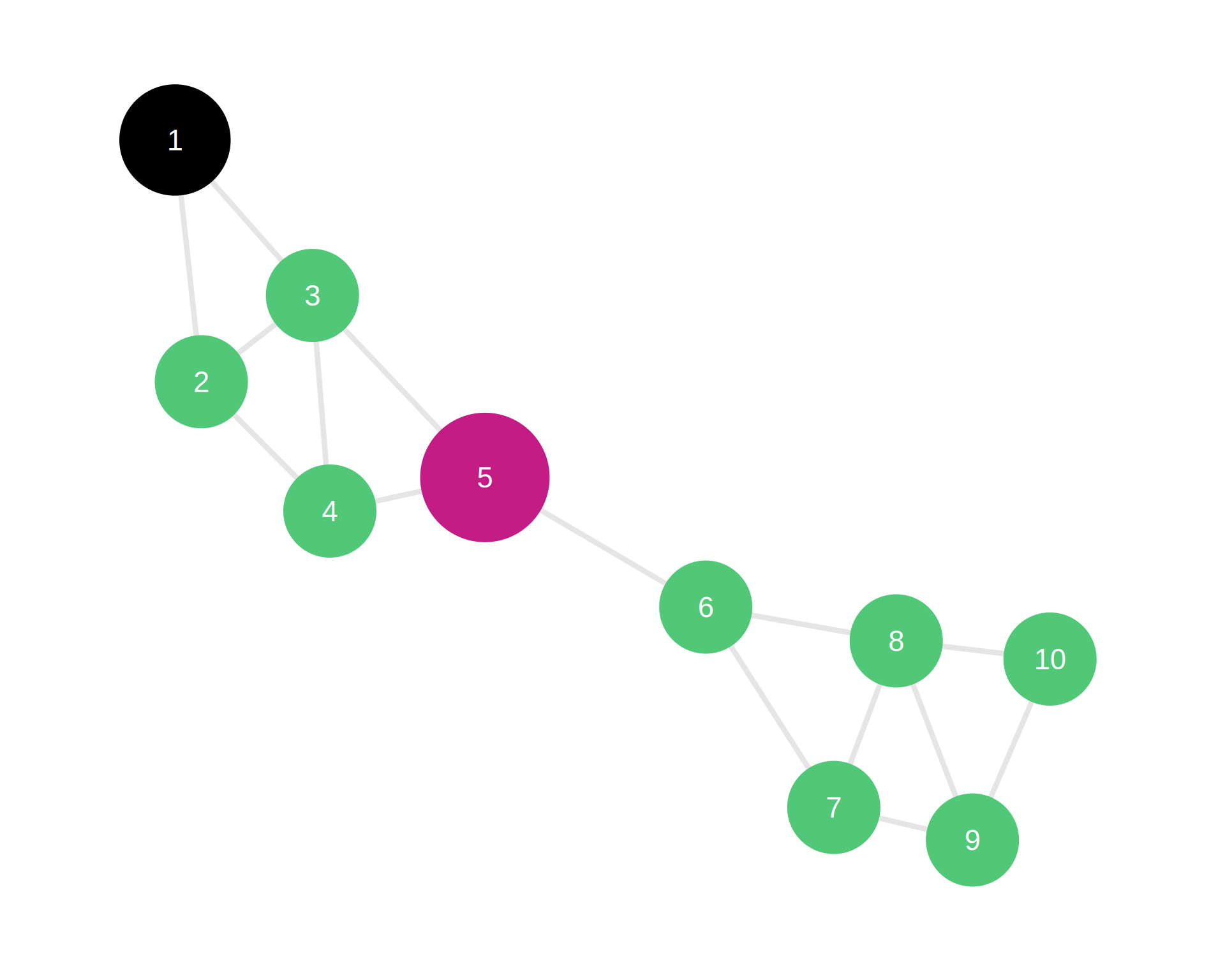
Note
Top network (Closed triad): Node A (magenta) has clustering coefficient = 1.0. Both neighbors B and C (emerald) are connected to each other.
Bottom network (Open triad): Node A (black) has clustering coefficient = 0.0. Neighbors B and C (emerald) are not connected.
Clustering Coefficient: Embeddedness
What High Clustering Means:
- Node is part of a dense, cohesive group
- High social capital and trust
- Information redundancy (everyone knows everyone)
- Strong group norms and social control
- Closure benefits (Coleman’s theory)
What Low Clustering Means:
- Node bridges disconnected groups
- Access to diverse, non-redundant information
- Weak tie advantages (Granovetter’s theory)
- Brokerage opportunities
- Less embedded, more autonomous
Trade-off: Closure (trust, coordination) vs. Brokerage (novelty, diversity)
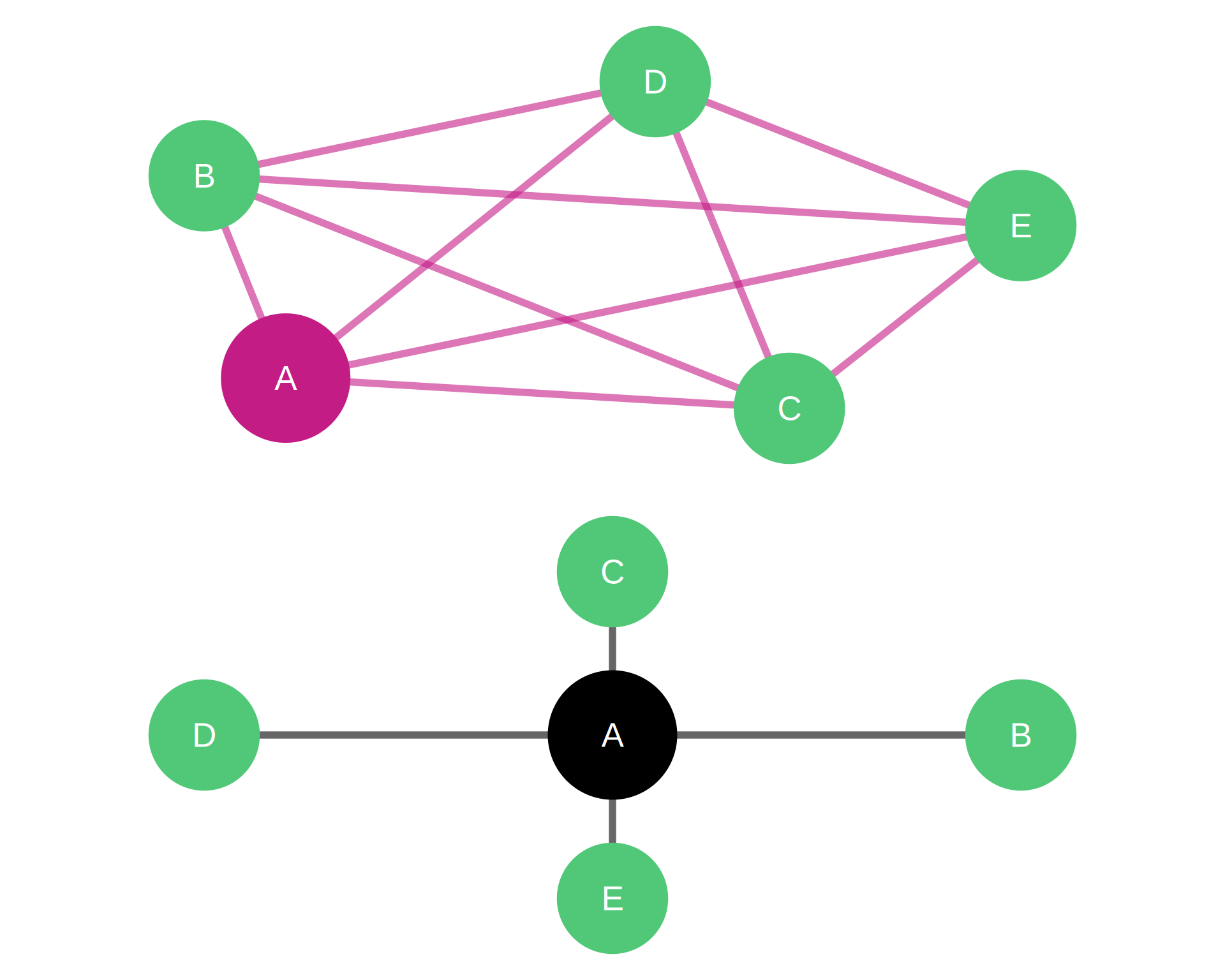
Note
Top network (High Clustering): Node A (magenta) is embedded in a dense, cohesive group where neighbors B, C, D, E (emerald) are highly interconnected. Closure benefits.
Bottom network (Low Clustering): Node A (black) bridges disconnected groups. Neighbors B, C, D, E (emerald) are not connected to each other. Brokerage opportunities.