


We start by importing some utility libraries to retrieve the .txt files containing the transcripts of a sample of commencement speeches.
Python
Copy
# %%
# Import libraries
#
import glob, os
import spacy
from rich.console import Console
from rich.table import Table
Then, we load one of the model languages made available by the spaCy people. Since we aren’t using word vectors, the small model “en_core_web_sm” is totally fine.
Python
Copy
# %% Load the model of the language to use for the pre-processing
nlp = spacy.load("en_core_web_sm")
Time to load the transcripts. The easiest way is to clone NLP-orgs-markets, the companion repo to this GitHub Page.
Python
Copy
# %%
# Load the transcripts for a sample of commencement speeches
#
# browse target folder
fdr = "../sampleData/commencementSpeeches/corpus"
in_fs = glob.glob(os.path.join(fdr, "*.txt"))
# load the transcripts into a dictionary
speeches = {}
for in_f in in_fs:
with open(in_f, "r") as f:
key = int(in_f.split("_")[1].rstrip(".txt"))
speeches[key] = f.read()
del key
Good to go: we create a nice table with Rich to populate with the outcome of spaCy. Note that spaCy associates a very large number of attributes to each token. The best way to get a closer understanding of these attributes (and their labels) is to browse the API of the library.
Python
Copy
# %%
# create a Rich's table to print the output of the spaCy's pipeline
console = Console()
# defin table properties
table = Table(
show_header=True,
header_style="bold #2070b2",
title="[bold] [#2070b2] A pre-processing NLP pipeline with spaCy[/#2070b2]",
)
# add columns
table.add_column('Token text')
table.add_column('Lemma')
table.add_column('POS')
table.add_column('DEP')
table.add_column('Alpha')
table.add_column('Stop')
# let's consider the first speech in the dictionary
doc = speeches[0]
# we retrieve the tokens' attributes and we add them to the table
for token in nlp(doc):
table.add_row(
token.text,
token.lemma_,
token.pos_,
token.dep_,
str(token.is_alpha),
str(token.is_stop),
)
# print the table
console.print(table)
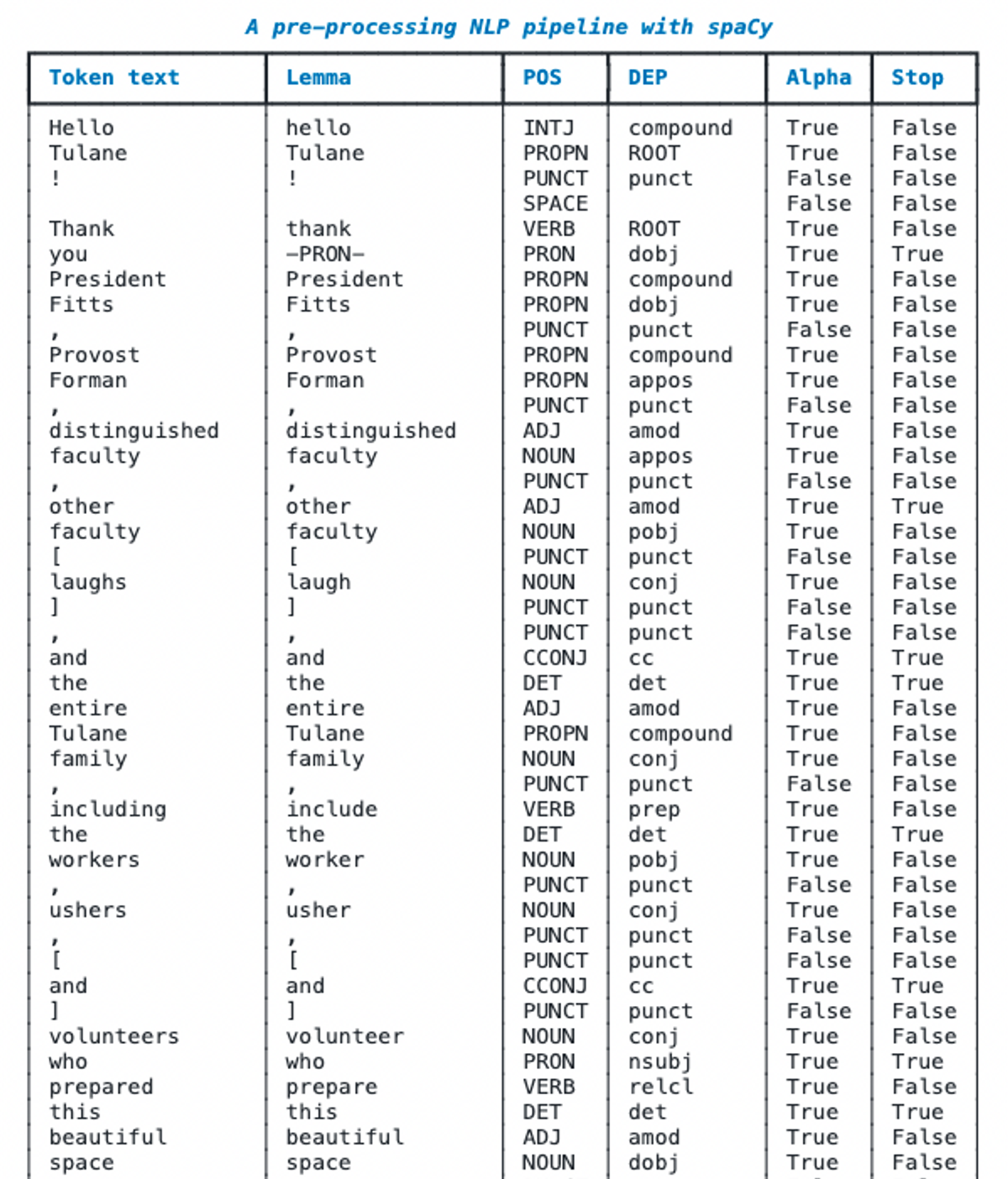
This snippet comes from the Python script “nlpPipelines/spacy_nlp_pipeline.py”, hosted in the GitHub repo simoneSantoni/NLP-orgs-markets.