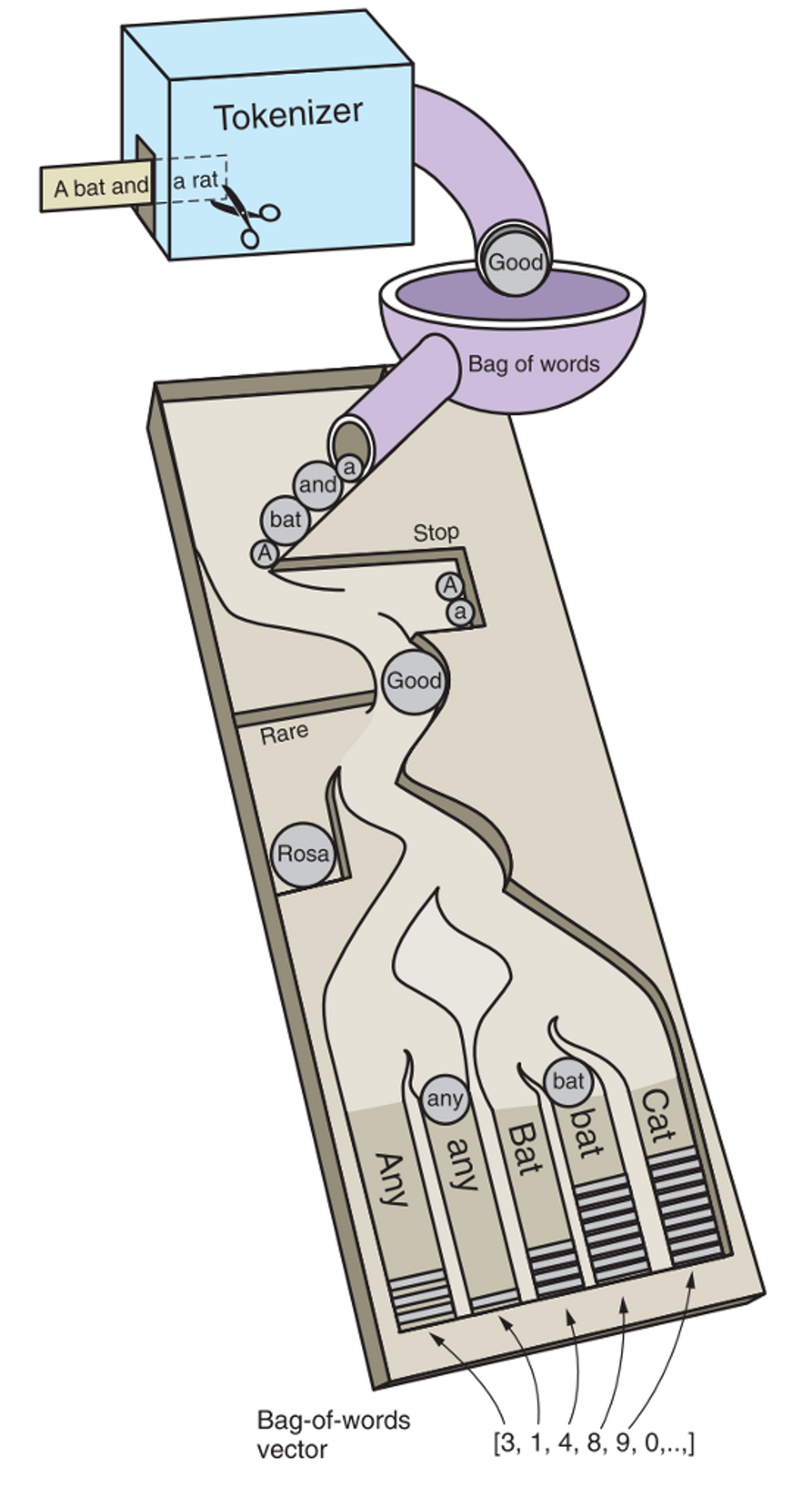
Let’s assume to have a corpus with a single document, which we want to express as a bag of words (BoW). The sample text we use is the first paragraph of the Wikipedia entry for BlackRock.
Python
Copy
>>> text = """
BlackRock, Inc. is an American multinational investment management corporation
based in New York City. Founded in 1988, initially as a risk management and
fixed income institutional asset manager, BlackRock is the world's largest
asset manager, with US$10 trillion in assets under management as of January
2022. BlackRock operates globally with 70 offices in 30 countries and clients
in 100 countries"
"""
In a BoW approach, the first step consists of tokenizing the document. See the below display infographic. So, we import NLTK’s TreebankWordTokenizer.
Python
Copy
>>> from nltk.tokenize import TreebankWordTokenizer
Now, we can tokenize ‘text’ as displayed below. TreebankWordTokenizer yields a list whose elements are individual tokens.
Python
Copy
>>> tkns = TreebankWordTokenizer().tokenize(text)
>>> print(tkns)
['BlackRock',
',',
'Inc.',
'is',
'an',
'American',
'multinational',
'investment',
'management',
'corporation',
'based',
'in',
'New',
'York',
'City.',
'Founded',
'in',
'1988',
',',
'initially',
'as',
'a',
'risk',
'management',
'and',
...
'clients',
'in',
'100',
'countries',
"''"]
Creating a bag of words means getting the cardinality of each unique tokens. In Pythonic terms, that equates to apply the collection’s Counter function over the tokenized document. That's it: the ‘bow’ object contains the occurrences of each unique token in the document.
Python
Copy
>>> from collections import Counter
>>> bow = Counter(tkns)
>>> print(bow)
Counter({'BlackRock': 3,
',': 4,
'Inc.': 1,
'is': 2,
'an': 1,
'American': 1,
'multinational': 1,
'investment': 1,
'management': 3,
'corporation': 1,
'based': 1,
'in': 5,
'New': 1,
'York': 1,
'City.': 1,
'Founded': 1,
'1988': 1,
'initially': 1,
'as': 2,
'a': 1,
'risk': 1,
'and': 2,
'fixed': 1,
'income': 1,
'institutional': 1,
...
'30': 1,
'countries': 2,
'clients': 1,
'100': 1,
"''": 1})
This snippet comes from the Python script “bow.py”, hosted in the GitHub repo simoneSantoni/NLP-orgs-markets.