

You’re supposed to adjudicate between helpful and unhelpful movie reviews from the IMDB database. For the sake of redundancy, your goal is to classify each movie review “i” into one of two categories:
0/not helpful: less than 30% of IMDB users found movie review “i” helpful
1/helpful: more than 70% of IMDB users found movie review “i” helpful
Data and file description
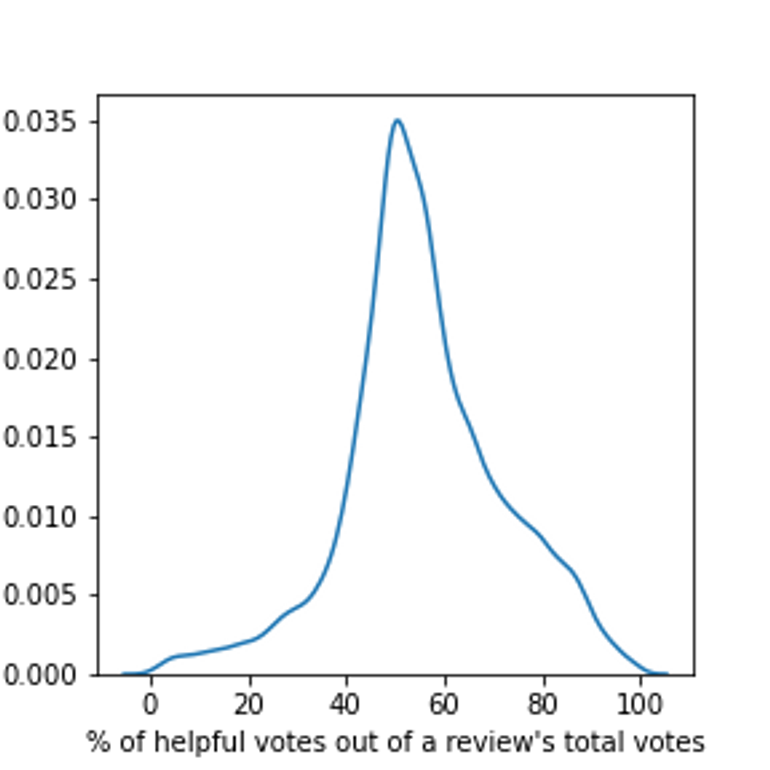
The training data (train.csv, see the download area below) contains 10,755 labeled reviews. The test data contains 5,071 unlabeled reviews (test.csv, see below). All the reviews included in the dataset have at least 80 votes. Contextual information: the following kernel density plot displays the distribution of the percentage of helpful votes out of the total votes each review received. The dataset for this FCP focuses on the distribution's left- and right-hand ‘tails’.
File description:
train.csv: your training data (N = 10,755). The first column, ‘’helpfulness_cat”, is the label of each training movie review; the second column, “imdb_user_review”, contains the text of the movie review.
test.csv: your test data (N = 5,071). The first column, “_id”, is a movie review-level identifier; the second column, “imdb_user_review”, is the unlabelled movie review to classify.
submission.csv: this is the file you’re asked to populate and submit. The first column, “_id”, is the review-level identifier reported in test.csv; the second column, ‘’helpfulness_cat”, will contain your predicted class label (0 or 1) for the corresponding line in text data. Note: i) please include the exact headers "_id, helpfulness_cat" in your submission — or just used the file I make available in the download area below; ii) stick with the movie identifiers included in the column “_id” of test.csv.
Download the files 
Guidelines
To carry out the classification task, you can use any classifier or combination of classifiers, any combination or selection of features, and either supervised, semi-supervised, or even transfer learning approaches. For example, the features may include (but are not limited to) BoW vectors, TFIDF vectors, vectors achieved with embedding algorithms, topic-to-document probabilities. In terms of estimators, you can use logistic regression, Naive Bayes Classifier, or any other estimator you think is appropriate given the nature of the task.