In this script, we aim to model the themes hidden in the ai_in_finance.json file, which contains 4K+ articles dealing with the topics of AI & financial services from The Wall Street Journal and The Financial Times. For a description of the corpus, see Lanzolla, Gianvito, Simone Santoni, and Christopher Tucci. "Unlocking value from AI in financial services: strategic and organizational tradeoffs vs. media narratives." In Artificial Intelligence for Sustainable Value Creation. Edward Elgar Publishing, 2021.
Mainly, we pursue two objectives:
to create a fully fledged (end-to-end) topic modeling project
to compare alternative competing topic modeling examples in terms of coherence score, one of the most popular statistical metrics to assess the fit of topic models
The script relies on Tomotopy to train an LDA model. The use of Gensim — another popular library implementing topic modeling — is limited to identify n-grams in the corpus.
Python
Copy
>>> import os
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> from matplotlib import rc
>>> import pandas as pd
>>> import spacy
>>> import tomotopy as tp
>>> from gensim.models import Phrases
We start by loading the sample data into a Panda DF.
Python
Copy
>>> os.chdir("../sampleData/econNewspaper")
>>> df = pd.read_csv("ft_wsj.csv")
Let's focus on the 2013 - 2019 timespan, which concentrates the large majority
of the data. To do that, we have to transform the ‘data’ field into a Pandas DF datetime object.
Python
Copy
>>> df.loc[:, "date"] = pd.to_datetime(df.loc[:, "date"])
>>> df.loc[:, "year"] = df["date"].dt.year
>>> df = df.loc[df["year"] >= 2013]
We can now pass the corpus of news through an NLP pipeline (step 3). Before doing that, we expand the set of stop-words, though. First, we create a list with out custom stop-words (step 1). Then, we change the attribute of these words in the spaCy model of the language (step 2).
Python
Copy
>>> stopwords = ["Mr", "Mr.", "$", "Inc.", "year"]. # step 1
>>> for item in stopwords: # step 2
nlp.vocab[item].is_stop = True
>>> docs_tokens, tmp_tokens = [], [] # step 3
>>> for doc in df.text.to_list():
tmp_tokens = [
token.lemma_
for token in nlp(doc)
if not token.is_stop
and not token.is_punct
and not token.like_num
and token.lemma_ != "say"
]
docs_tokens.append(tmp_tokens)
tmp_tokens = []
To increase the interpretability of the topics we are about to render, we try to identify the bi-grams and tri-grams included in the corpus. For example, the two lexemes ‘decision’ and ‘making’ might be joined into the single lexeme ‘decision-making’. To accomplish this, we rely on Gensim’s phrases ‘method’, included in the module ‘models’ module. An important caveat applies here: we do not want to form n-grams involving popular words that, for whatever reason, have not filtered out in the pipeline. The dictionary ‘common_terms’ contains a sample of these common words.
Python
Copy
>>> common_terms = [
u"of",
u"with",
u"without",
u"and",
u"or",
u"the",
u"a",
u"not",
u"be",
u"to",
u"this",
u"who",
u"in",
]
By using the ‘Phrases’ method, we train one model capturing bi-grams (see step 1) and a second model capturing tri-grams (see step 2).
Python
Copy
>>> bigram = Phrases( # step 1
docs_tokens,
min_count=50,
threshold=5,
max_vocab_size=50000,
common_terms=common_terms,
)
>>> trigram = Phrases( # step 2
bigram[docs_tokens],
min_count=50,
threshold=5,
max_vocab_size=50000,
common_terms=common_terms,
)
Thanks to these two models, we can process the tokenized documents and join the tokens associated with bi- or tri-grams.
Python
Copy
>>> docs_phrased = [trigram[bigram[line]] for line in docs_tokens]
We believe the documents are clean enough for training the topic modeling. Using Tomotopy, it is necessary to wrap the pre-processed documents in a Corpus class object, which has to be initialized (step 1) and populated (step 2).
Python
Copy
>>> corpus = tp.utils.Corpus() # step 1
>>> for item in docs_phrased: # step 2
corpus.add_doc(words=item)
An integral part of the Topic Modeling process is exploring the fit of alternative models, i.e., models retaining different number of topics. In this example, models are assessed against the Coherence Score metric as per the ‘u_mass’ version (the lower the score, the better the model fit).
In step 1, we create an empty dictionary to store the scores of the different models. In step 2, we let the number of retained topics to change across models and, for each model, we record the associated Coherence Score
Python
Copy
>>> cvs = {} # step 1
>>> for topic_number in range(1, 16, 1): # step 2
mdl = tp.LDAModel(k=topic_number, corpus=corpus)
for i in range(0, 100, 10):
mdl.train(10)
print("Iteration: {}\tLog-likelihood: {}".format(i, mdl.ll_per_word))
coh = tp.coherence.Coherence(mdl, coherence="u_mass")
cvs[topic_number] = coh.get_score()
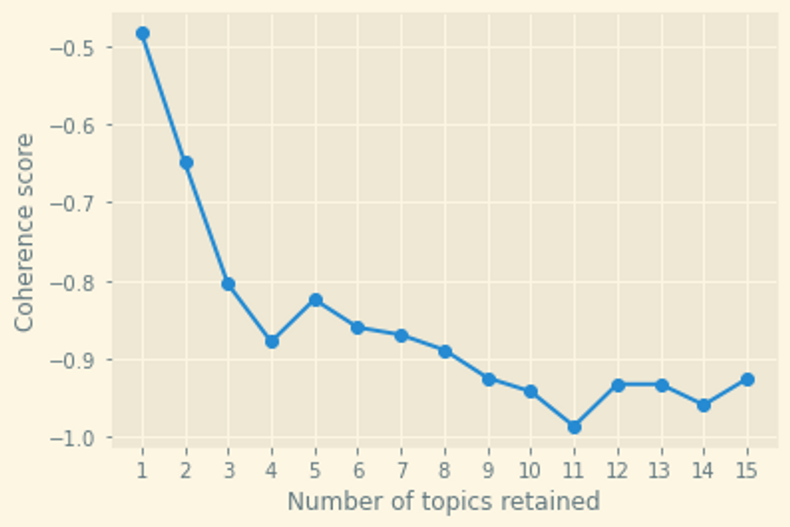
The below chart displays the fit of the fifteen competing models, retaining between one and fifteen topics.
Python
Copy
>>> fig = plt.figure(figsize=(6, 4))
>>> ax = fig.add_subplot(111)
>>> ax.plot(cvs.keys(), cvs.values(), "o-")
>>> ax.set_xlabel("Number of topics retained")
>>> ax.set_ylabel("Coherence score")
>>> ax.set_xticks(range(1, 15, 1))
>>> plt.show()
The visual inspection of the chart indicates the best fit model is the one with eleven topics. That said, in order to make a better informed choice about the best model, further alternatives should be considered (i.e., a sample of models retaining between one and two hundred topics).
Hence, we train our best fit model.
Python
Copy
>>> for i in range(0, 100, 10):
best_mdl.train(10)
print("Iteration: {}\tLog-likelihood: {}".format(i, best_mdl.ll_per_word))
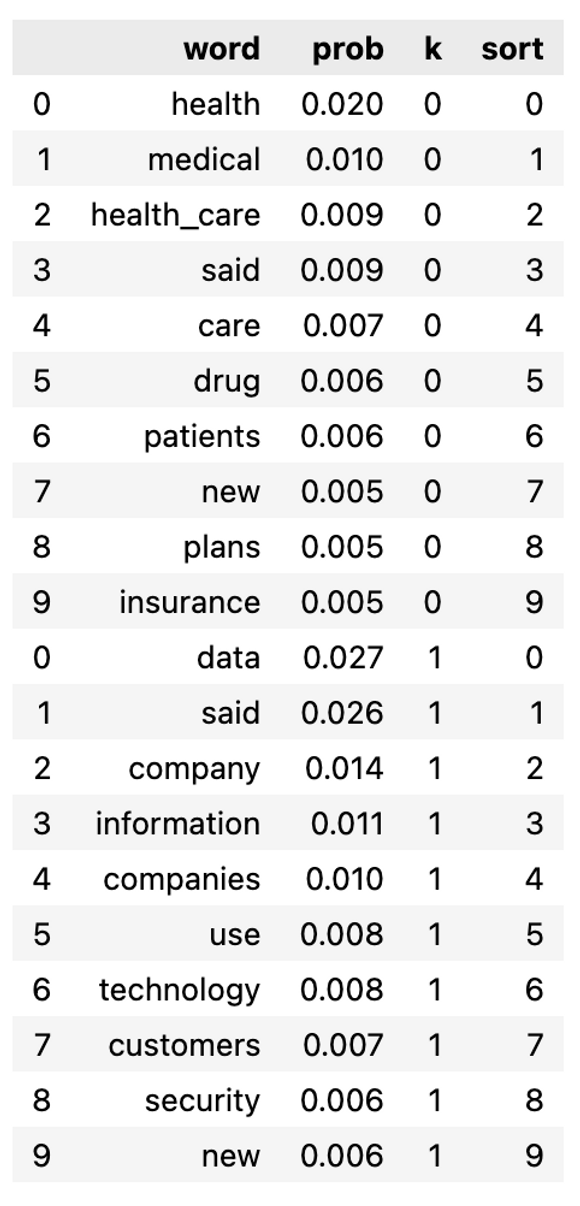
Using the ‘get_topic_words’ attribute, we retrieve the topic-to-word probabilities, a key outcome of topic modeling. The estimated probabilities are arranged into a Pandas DF.
Python
Copy
>>> wt = pd.DataFrame()
>>> for k in range(best_mdl.k):
words, probs = [], []
for word, prob in best_mdl.get_topic_words(k):
words.append(word)
probs.append(prob)
tmp = pd.DataFrame(
{
"word": words,
"prob": np.round(probs, 3),
"k": np.repeat(k, len(words)),
"sort": np.arange(0, len(words)),
}
)
wt = pd.concat([wt, tmp], ignore_index=False)
del tmp
>>> wt.head(1).T
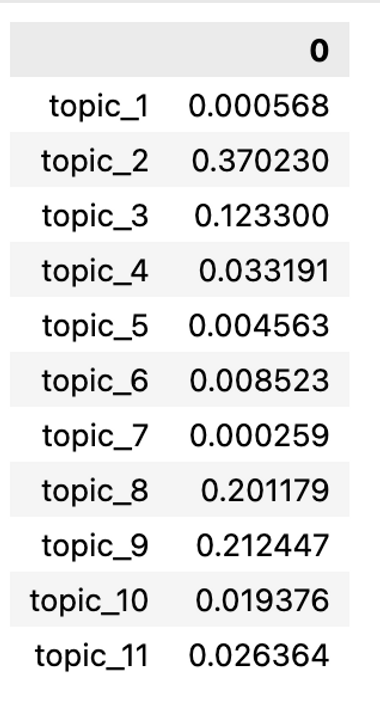
The second outcome of topic modeling we retrieve consists of the topic-to-document probabilities, which we retrieve using the ‘get_topic_dist’ attribute, available for any document included in the LDA corpus used for the training.
Python
Copy
>>> td = pd.DataFrame(
np.stack([doc.get_topic_dist() for doc in best_mdl.docs]),
columns=["topic_{}".format(i + 1) for i in range(best_mdl.k)],
)
>>> td.head(1).T
This snippet comes from the Python script “barebone_tomotopy.py”, hosted in the GitHub repo simoneSantoni/NLP-orgs-markets.