training and evaluating topic models retaining a different number of topics
folding in unseen documents into the retained topic model (that is the best fit model)
Note: the full notebook, leadership_natural_experiment.ipynb, is pretty long. Here, I emphasize some key steps. The data for the training phase contain 1,156 abstracts published in the leading leadership journal, namely, The Leadership Quarterly. The unseen documents concern 87 abstracts of articles published across economics, sociological, and political science journals.
Having pre-processed the abstracts, we create two Gensim class objects, a dictionary (step 1) and a corpus (step 2).
Python
Copy
>>> DICT = Dictionary(DOCS_PHRASED) # step 1
>>> CORPUS = [DICT.doc2bow(doc) for doc in DOCS_PHRASED] # step 2
The existing literature suggests there are 29 topics represented in The Leadership Quarterly. Then, we fit a topic model with 29 topics.
Python
Copy
>>> N_TOPICS = 29
>>> LDA_MALLET = gensim.models.wrappers.LdaMallet(
MALLET_PATH,
corpus=CORPUS,
num_topics=N_TOPICS,
id2word=DICT,
random_seed=123
)
>>> LDA_MALLET.print_topics(num_topics=N_TOPICS, num_words=5)
Shell
Copy
[(0,
'0.140*"development" + 0.023*"special" + 0.022*"developmental"
+ 0.021*"multi_level" + 0.017*"primarily"'),
(1,
'0.058*"context" + 0.046*"effective" + 0.039*"develop"
+ 0.031*"career" + 0.025*"set"'),
...
(27,
'0.071*"perspective" + 0.044*"dynamic" + 0.036*"system"
+ 0.034*"emerge" + 0.030*"proposition"'),
(28,
'0.208*"group" + 0.062*"identity" + 0.034*"hypothesis"
+ 0.030*"member" + 0.026*"information"')]
The qualitative inspection of word-to-topic probabilities indicate some topics are hard to interpret. Hence, we decide to explore models retaining different numbers of topics. To do that, we create a function to train an LDA model and to store its coherence score.
Python
Copy
>>> def compute_coherence_values(dictionary, corpus, texts, limit, start, step):
"""
Compute c_v coherence for various number of topics
Parameters:
-----------
dictionary : Gensim dictionary
corpus : Gensim corpus
texts : List of input texts
limit : Max number of topics
Returns:
--------
model_list : List of LDA topic models
coherence_values : Coherence values corresponding to the LDA model
with respective number of topics
"""
coherence_values = []
model_list = []
mallet_path = MALLET_PATH
for num_topics in range(start, limit, step):
model = gensim.models.wrappers.LdaMallet(mallet_path,
corpus=corpus,
num_topics=num_topics,
id2word=dictionary,
random_seed=123)
model_list.append(model)
coherencemodel = CoherenceModel(model=model,
texts=texts,
dictionary=dictionary,
coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
We can now deploy the function to search for the best fit LDA model. We are sampling 20 alternative topics models (between 10 and 30 topics).
Python
Copy
>>> LIMIT, START, STEP = 40, 1, 1
>>> MODEL_LIST, COHER_VALS = compute_coherence_values(dictionary=DICT,
corpus=CORPUS,
texts=DOCS_PHRASED,
start=START,
limit=LIMIT,
step=STEP)
Let’s plot the coherence scores included in the COHER_VALS list
Python
Copy
>>> FIG = plt.figure(figsize=(6, 4))
>>> AX = FIG.add_subplot(1, 1, 1)
>>> AX.plot(X, Y, marker='o', color='b', ls='-')
>>> AX.set_xlabel("Number of topics retained")
>>> AX.set_ylabel("Coherence score")
>>> AX.set_xticks(np.arange(10, 30, 1))
>>> AX.axvline(x=11, ymin=0, ymax=1, color='r')
>>> AX.grid(True, ls='--')
>>> plt.show()
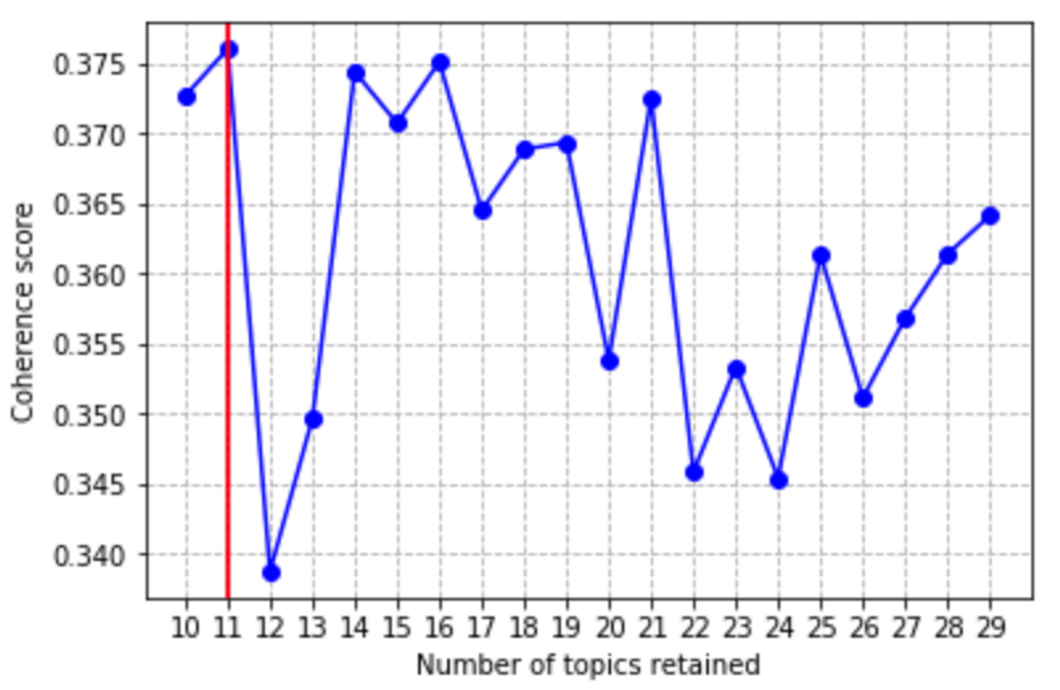
The model with ten and eleven topics show relatively large coherence scores vis a’ vis alternative models. For the sake of parsimony, we consider the model with ten topics and we inspect it qualitatively.
Python
Copy
>>> N_TOPICS = 10
>>> LDA_MALLET = gensim.models.wrappers.LdaMallet(MALLET_PATH,
corpus=CORPUS,
num_topics=N_TOPICS,
id2word=DICT,
random_seed=123)
>>> LDA_MALLET.print_topics(num_topics=N_TOPICS, num_words=10)
Shell
Copy
[(0,
'0.042*"context" + 0.030*"woman" + 0.024*"difference" + 0.024*"power"
+ 0.020*"role" + 0.017*"gender" + 0.017*"practice" + 0.016*"female"
+ 0.013*"culture" + 0.012*"position"'),
(1,
'0.034*"perception" + 0.033*"affect" + 0.030*"role" + 0.028*"emotion"
+ 0.028*"positive" + 0.026*"emotional" + 0.026*"negative"
+ 0.017*"network" + 0.016*"influence" + 0.016*"collective"'),
(2,
'0.056*"transformational" + 0.043*"subordinate" + 0.026*"rating"
+ 0.021*"trait" + 0.017*"associate" + 0.016*"experience"
+ 0.016*"significant" + 0.016*"personality" + 0.014*"high"
+ 0.014*"analysis"'),
(3,
'0.046*"development" + 0.027*"perspective" + 0.017*"develop"
+ 0.015*"political" + 0.015*"include" + 0.013*"purpose"
+ 0.013*"interest" + 0.012*"view" + 0.012*"multiple" + 0.010*"year"'),
(4,
'0.054*"employee" + 0.048*"work" + 0.034*"lmx" + 0.023*"job"
+ 0.023*"supervisor" + 0.021*"perceive" + 0.019*"authentic"
+ 0.018*"mediate" + 0.016*"hypothesis" + 0.015*"satisfaction"'),
(5,
'0.024*"understand" + 0.020*"effective" + 0.019*"vision"
+ 0.017*"problem" + 0.017*"cognitive" + 0.015*"strategy" + 0.014*"lead"
+ 0.013*"dynamic" + 0.013*"proposition" + 0.013*"identify"'),
(6,
'0.106*"performance" + 0.085*"team" + 0.033*"member" + 0.030*"ceo"
+ 0.021*"management" + 0.019*"skill" + 0.018*"firm" + 0.018*"decision"
+ 0.017*"share" + 0.015*"strategic"'),
(7,
'0.029*"level" + 0.024*"increase" + 0.023*"ethical" + 0.019*"develop"
+ 0.017*"impact" + 0.016*"moral" + 0.015*"structure" + 0.014*"reveal"
+ 0.013*"practice" + 0.012*"integrity"'),
(8,
'0.051*"charismatic" + 0.041*"change" + 0.035*"manager" + 0.030*"time"
+ 0.025*"charisma" + 0.018*"style" + 0.014*"content" + 0.013*"crisis"
+ 0.012*"type" + 0.010*"managerial"'),
(9,
'0.073*"group" + 0.040*"effectiveness" + 0.030*"task" + 0.023*"condition"
+ 0.022*"identity" + 0.021*"individual" + 0.019*"emergence" + 0.017*"show"
+ 0.015*"response" + 0.014*"characteristic"')]
The ten-topic model seems to provide an accurate representation of the leadership literature’s research themes. So, we can proceed with the next step, which consists of getting the topic representations for the 87 unseen abstracts.
Having pre-processed the unseen documents, we carry out the following steps:
creating a new Gensim corpus with the pre-processed, unseen documents (step 1)
getting the document-to-topic probabilities for the items included in the new corpus (step 2)
storing the document-to-topic probabilities in a Pandas DF for further post-processing (step 3)
Python
Copy
>>> NEW_CORPUS = [DICT.doc2bow(doc) for doc in DOCS_PHRASED] # step 1
>>> TRANSF_CORPUS = LDA_MALLET_G.get_document_topics(NEW_CORPUS) # step 2
>>> DOC_TOPIC_M = [] # step 3
>>> for id, doc in enumerate(TRANSF_CORPUS):
for topic in np.arange(0, 10, 1):
topic_n = doc[topic][0]
topic_prob = doc[topic][1]
DOC_TOPIC_M.append([id, topic, topic_prob])
>>> DF = pd.DataFrame(DOC_TOPIC_M)
This snippet comes from the Python script leadership_natural_experiment.ipynb, hosted in the GitHub repo simoneSantoni/NLP-orgs-markets.