Motivation: why shall we weigh token cardinalities?
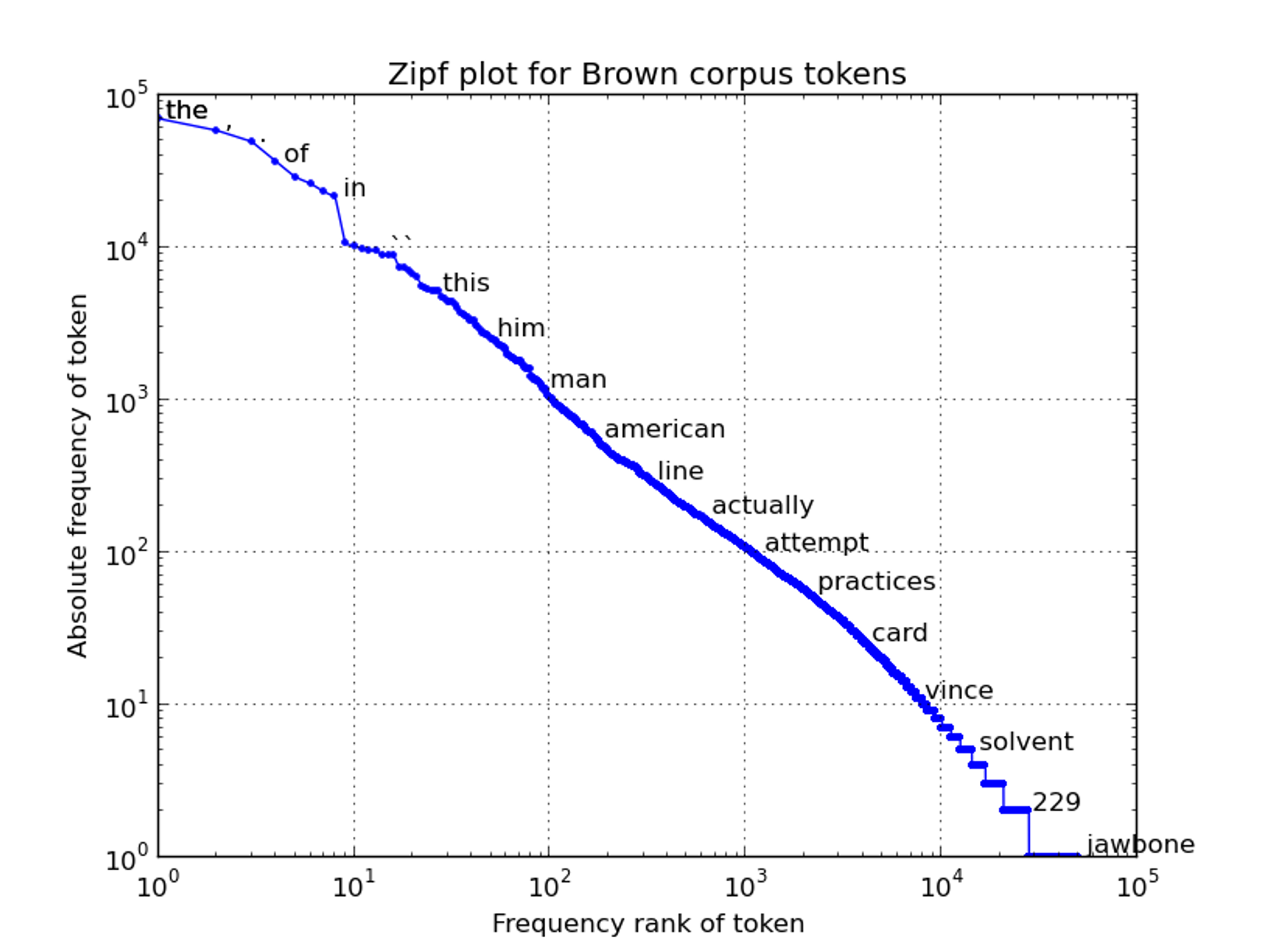
The distribution of words in a corpus of text is sharply uneven: the most popular words are disproportionately popular while the least popular words have a few occurrences. The below-displayed chart reports, for example, the frequency of tokens in the Brown corpus.
In their book ‘Speech and Language Recognition’, Martin and Jurafsky observe that:
Raw (term) frequency is very skewed and not very discriminative. If we want to know what kinds of contexts are shared by cherry and strawberry but not by digital and information, we’re not going to get good discrimination from words like the, it, or they, which occur frequently with all sorts of words and aren’t informative about any particular word. We saw this also [omitted] for the Shakespeare corpus; the dimension for the word good is not very discriminative between plays; good is simply a frequent word and has roughly equivalent high frequencies in each of the plays.
(chapter 6, page 12)
Using the term frequency-inverse document frequency (TFIDF) approach helps to cope with that problem. TFIDF weighs the cardinality of each token by two factors:
term frequency, namely, the frequency of token t in document d
document frequency for token t, that is, the number of documents t occurs in
Especially, in the TFIDF framework, a token’s weight is expressed as the product of term frequency and inverse document frequency (typically, the ratio between the total number of documents in the collection, and the number of documents in which term t occurs).
Let’s see the TFIDF in action in the ‘ai in finance news corpus’. First, we import the required libraries, though.
Python
Copy
>>> from collections import Counter, OrderedDict
>>> import json
>>> import numpy as np
>>> import pandas as pd
>>> import spacy
>>> nlp = spacy.load('en_core_web_sm')
Then, we load the data, which are stored in a line-by-line json file.
Python
Copy
>>> in_f = "../sampleData/econNewspaper/ai_in_finance.json"
>>> df = pd.json_normalize([json.loads(line) for line in open(in_f)])
In the interest of time, we filter in the first 100 articles.
Python
Copy
>>> docs = df.loc[0:99, "text"].tolist()
Drawing on spaCy, we tokenized the documents.
Python
Copy
>>> docs_tkns = []
>>> for doc in docs:
tmp = [
token
for token in nlp(doc)
if (not token.is_stop) & (not token.is_punct) & (token.is_alpha)
]
docs_tkns.append(tmp)
del tmp
The object ‘voc’ is the vocabulary for the corpus of 100 documents.
Python
Copy
>>> voc = sorted(set(sum(docs_tkns, [])))
Now, it’s time to operate the TFIDF transformation:
in step 1, we create an empty container
by iterating over the retained 100 documents, in step 2, we borrow the unique tokens included in ‘voc’
in step 3, we create a vocabulary specific to the tokenized document at hand in the loop
by iterating over each token included in ‘tkns_count’, in step 4, we compute the term frequency factor — which will be used to compute the TFIDF representation. As suggested in the literature and practice, we work in the log space
in step 5, we create the scalar ‘docs_with_key’ to record the count of document where ‘k’ appears
in step 6, we iterate over the documents in the corpus to update ‘docs_with_key’in se
in step 7, we compute the inverse of document frequency. As suggested in the literature and practice, we work in the log space
in step 8, we compute TFIDF weights
in step 9, we append the document vector to the vector space
Python
Copy
>>> vector_space = [] # step 1
for doc in docs_tkns:
vector = OrderedDict((token, 0) for token in voc) # step 2
tkns_count = Counter(doc) # step 3
for k, v in tkns_count.items():
tf = np.log10(v + 1) # step 4
docs_with_key = 0 # step 5
for doc_ in docs_tkns: # step 6
if k in doc_:
docs_with_key += 1
if docs_with_key: # step 7
idf = np.log10(len(docs_tkns) / docs_with_key)
else:
idf = 0
vector[k] = np.round(tf * idf, 4) # step 8
vector_space.append(vector) # step 9
This snippet comes from the Python script “tfidf.py”, hosted in the GitHub repo simoneSantoni/NLP-orgs-markets.